论文链接:
“ 金融时间序列预测具有高度重要性与挑战性。传统方法通常对时间序列数据标准化后输入模型,导致关键信息丢失;且模型依赖固定变量数或回看窗口长度,限制了扩展性;此外,预测的可解释性与不确定性量化仍需深入研究。为解决这些问题,本文首先...
金融时间序列预测难题咋解?新方法准确率提升13.48%
论文链接:
“ 金融时间序列预测具有高度重要性与挑战性。传统方法通常对时间序列数据标准化后输入模型,导致关键信息丢失;且模型依赖固定变量数或回看窗口长度,限制了扩展性;此外,预测的可解释性与不确定性量化仍需深入研究。为解决这些问题,本文首先构建了多样化的金融图文数据集(FVLDB),并提出不确定性调整组相对策略优化(UARPO)方法,使模型不仅能输出预测结果,还能分析预测的不确定性。在此基础上,开发了基于UARPO微调的多模态预训练模型,支持对FVLDB金融时间序列的推理、预测与分析理解。实验表明,展现了强适应性与扩展性;经UARPO微调后,其在高置信组的预测准确率较GPT-4o提升约13.48%,验证了强化学习微调在多模态大模型(尤其是金融时间序列预测任务)中的有效性。”
01
背景
时间序列预测因广泛应用于交通、气象、能源、金融等领域而备受关注。其中,金融时间序列因受宏观/微观因素、多空博弈等复杂影响,具有适应性市场特性——历史模式一旦被交易者利用,便会失效,导致预测难度极高。
02
问题定义
本文旨在解决金融时序预测中的以下核心问题:
1. 传统时间序列处理中标准化导致的信息损失问题;
2. 模型对固定配置(如回看窗口、变量数量)的依赖导致的扩展性不足;
3. 大模型推理能力在时间序列任务中未充分利用的问题;
4. 预测结果的可解释性与不确定性量化缺失,影响实际应用可靠性。
03
方法
3.1 核心模型:
是基于多模态大模型(MLM)的金融时间序列预测模型,其整体流程如图所示。模型以30亿参数的多模态大模型(如Qwen2.5-VL-3B)为骨干,通过UARPO方法在FVLDB数据集上微调,支持显式考虑预测不确定性的推理与预测任务。
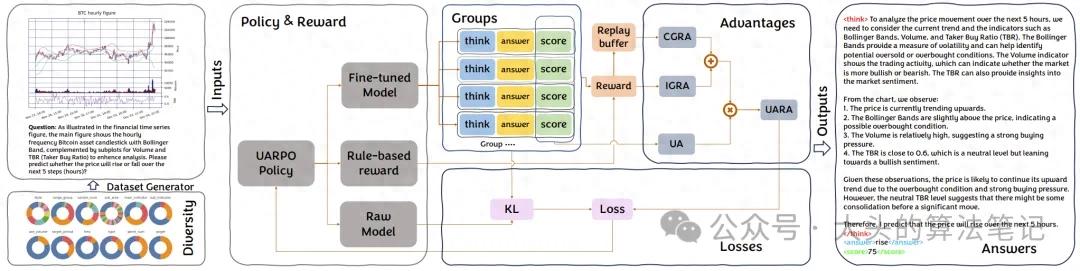
3.2 关键方法:UARPO
UARPO是对GRPO(组相对策略优化)的改进,通过引入组内相对优势(IGRA)、组间相对优势(CGRA)与不确定性调整(UARA),解决金融时间序列的非平稳性与不确定性问题。
3.2.1 优化目标
UARPO的优化目标:
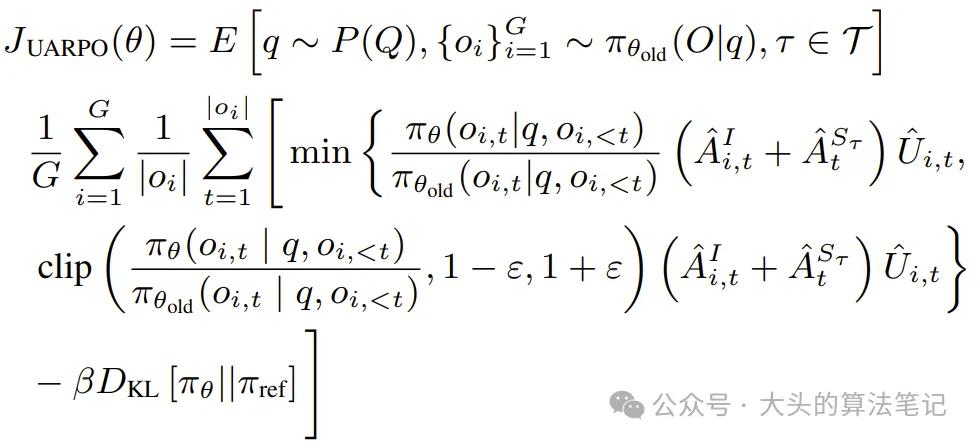
其中pi_{theta}与pi_{}为当前与旧策略模型;q与o_i为从问题数据集与旧策略采样的问题与输出;A_{i, t}^{I}(组内相对优势)定义为:
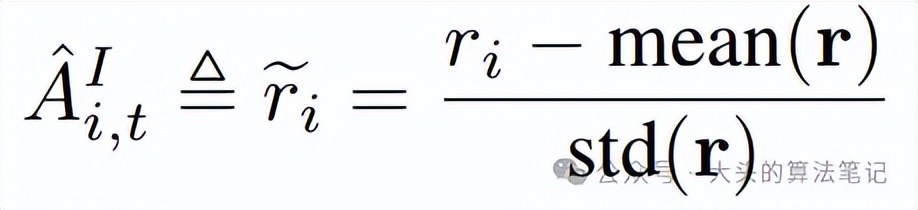
其中r=
r_0, r_1, ..., r_G
为组内奖励;A_{t}^{S_{tau}}(组间相对优势)定义为:
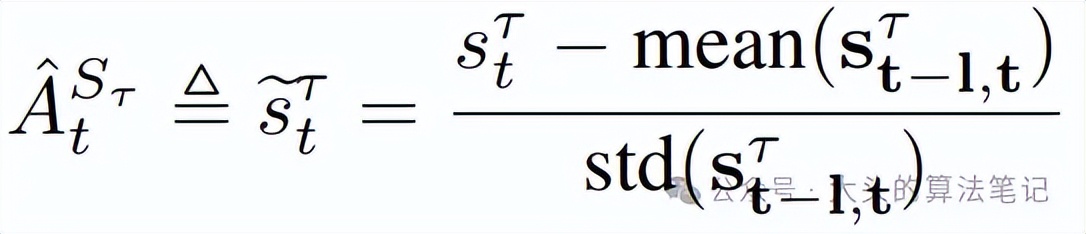
其中s_{t}^{tau}为当前组在目标tau下的平均奖励,s_{t-1, t}^{tau}为近期窗口内多步奖励的集合;不确定性调整定义为:
其中alpha为可调系数,score为模型推理的置信度得分。
3.2.2 算法流程
UARPO的迭代过程如算法所示

3.3 奖励与不确定性设计
为引导模型学习,UARPO设计了以下奖励:
准确率奖励:衡量预测与真实涨跌结果的一致性;
完成长度奖励:鼓励推理文本长度扩展(≤200 时逐步增加奖励);
格式奖励:约束模型学习目标输出格式;
置信度得分:模型基于输入与推理过程输出置信度,量化预测不确定性,支持风险评估。
04
实验
4.1 数据集:FVLDB
FVLDB是包含10,000+金融时间序列图文对的多样化数据集,涵盖全球股市指数、比特币等加密资产数据。其多样性体现在:资产类型(股票、加密货币等);预测任务类别(价格、波动率等);历史序列长度、频率、指标种类;图像风格(如K线图、技术指标图)。
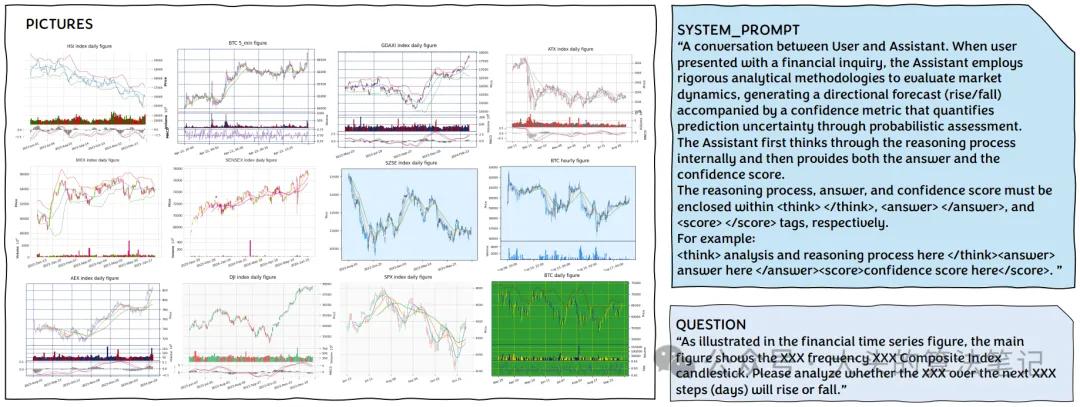
4.2 实验设置
模型骨干:Qwen2.5-VL-3B(30亿参数);
基线模型:原始Qwen2.5-VL-3B、Qwen2.5-VL-7B(70亿参数)、GPT-4o、GRPO微调的Qwen2.5-VL-3B、Naive模型(延续历史趋势);
训练配置:Adam优化器(学习率1e-6),2轮微调;
硬件:2张80G A100 GPU。
4.3 实验结果
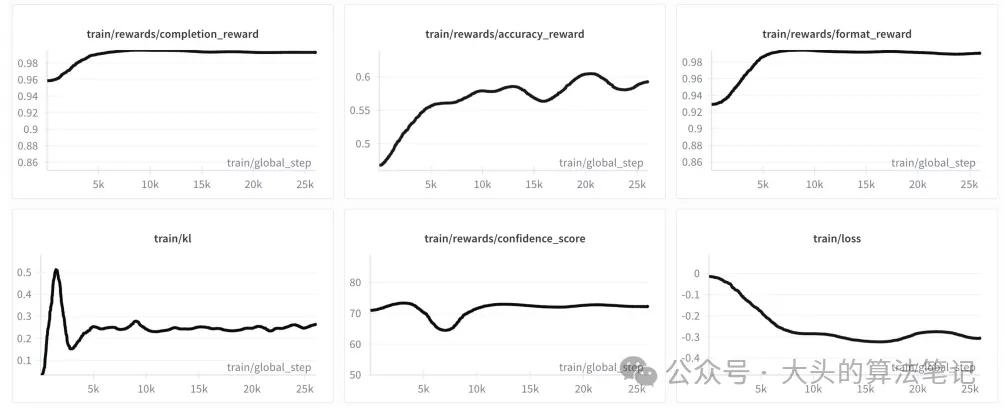
4.3.1 训练过程
UARPO微调过程中,格式奖励与完成长度奖励在训练早期快速上升并稳定,准确率奖励持续增长,损失值不断下降,表明模型有效学习了目标格式、推理深度与预测能力。
4.3.2 预测性能
下表展示了各模型在波动率与价格预测任务中的准确率对比:
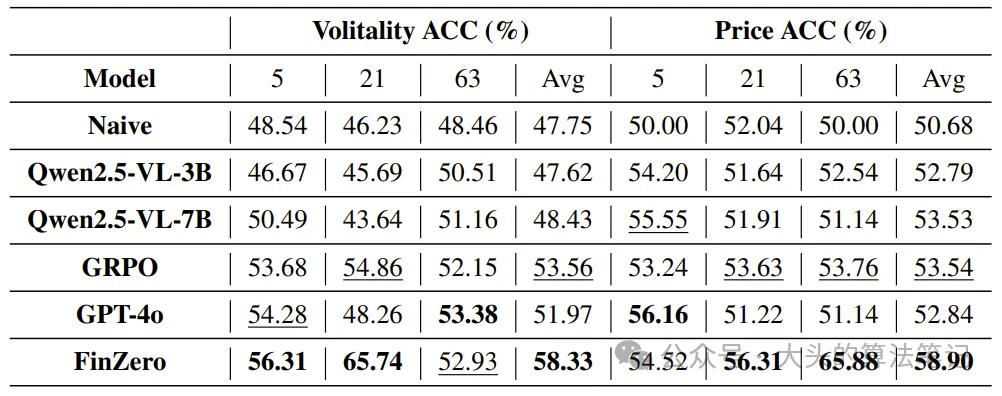
(30亿参数)在波动率与价格预测的平均准确率上均超越更大参数模型(如GPT-4o、Qwen2.5-VL-7B),验证了UARPO微调的有效性。
4.3.3 置信度分组分析
下表显示了按置信度得分分组的预测准确率:
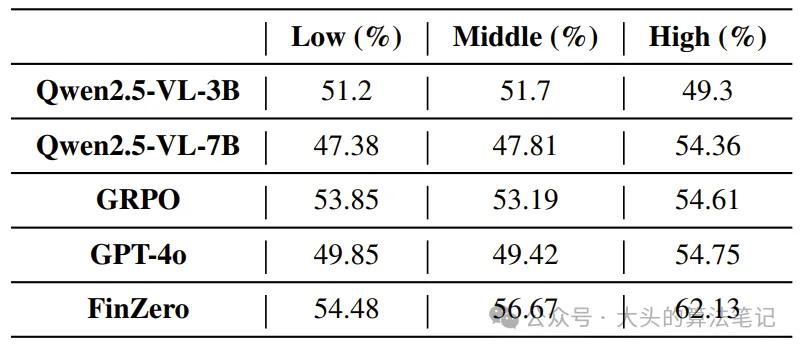
的高置信组准确率较GPT-4o提升约13.5%,且置信度与准确率呈强正相关,表明其不确定性量化可靠,支持更可信的金融决策。
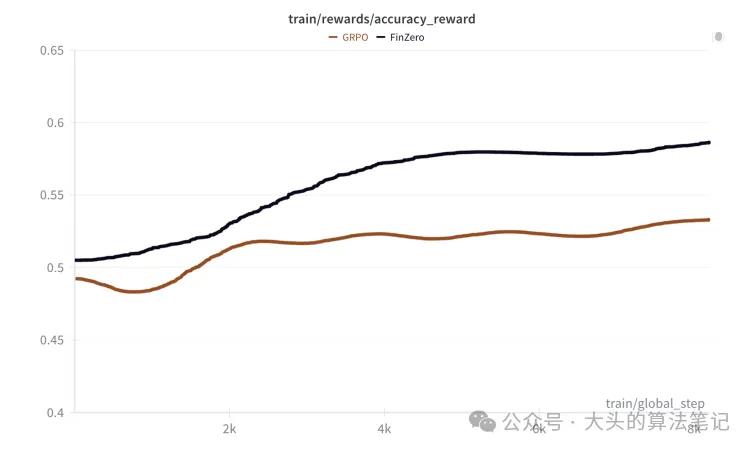
4.3.4 微调趋势对比
在微调过程中的准确率增长趋势显著优于其他模型,进一步验证了UARPO的有效性。
预测 模型 UARPO 奖励 金融 时间序列
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战