爬虫 -
爬虫(Web )是指通过编写 程序从互联网上自动提取信息的过程。
爬虫的基本流程通常包括发送 HTTP 请求获取网页内容、解析网页并提取数据,然后存储数据。
的丰富生态使其成为开发爬虫的热门语言,特别是由于其强大的库支持...
Python爬虫中的BeautifulSoup库,解析HTML轻松提取数据
爬虫 -
爬虫(Web )是指通过编写 程序从互联网上自动提取信息的过程。
爬虫的基本流程通常包括发送 HTTP 请求获取网页内容、解析网页并提取数据,然后存储数据。
的丰富生态使其成为开发爬虫的热门语言,特别是由于其强大的库支持。
一般来说,爬虫的流程可以分为以下几个步骤:
本章节主要介绍 ,它是一个用于解析 HTML 和 XML 文档的 库,能够从网页中提取数据,常用于网页抓取和数据挖掘。
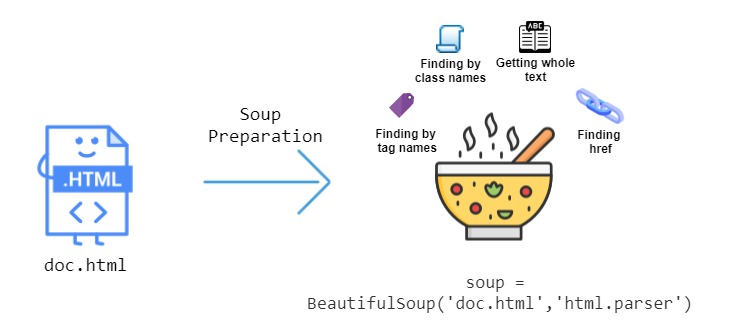
是一个用于从网页中提取数据的 库,特别适用于解析 HTML 和 XML 文件。
能够通过提供简单的 API 来提取和操作网页中的内容,非常适合用于网页抓取和数据提取的任务。
安装
要使用 ,需要安装 和 lxml 或 html.(一个 HTML 解析器)。
我们可以使用 pip 来安装这些依赖:
pip install beautifulsoup4 pip install lxml # 推荐使用 lxml 作为解析器(速度更快)
如果你没有 lxml,可以使用 内置的 html. 作为解析器。
基本用法
用于解析 HTML 或 XML 数据,并提供了一些方法来导航、搜索和修改解析树。
常见的操作包括查找标签、获取标签属性、提取文本等。
要使用 ,需要先导入 ,并将 HTML 页面加载到 对象中。
通常,你会先用爬虫库(如 )获取网页内容:
实例
from bs4
# 使用 获取网页内容
url = '' # 抓取bing搜索引擎的网页内容
= .get(url)
# 使用 解析网页
soup = (.text, 'lxml') # 使用 lxml 解析器
# 解析网页内容 html. 解析器
# soup = (.text, 'html.')
获取网页标题:
实例
from bs4
# 指定你想要获取标题的网站
url = '' # 抓取bing搜索引擎的网页内容
# 发送HTTP请求获取网页内容
= .get(url)
# 中文乱码问题
. = 'utf-8'
# 确保请求成功
if . == 200:
# 使用解析网页内容
soup = (.text, 'lxml')
# 查找标签
= soup.find('title')
# 打印标题文本
if :
print(.())
else:
print("未找到标签")
else:
print("请求失败,状态码:", .)
执行以上代码,输出标题为:
搜索 - Microsoft 必应
中文乱码问题
使用 库抓取中文网页时,可能会遇到编码问题,导致中文内容无法正确显示,为了确保能够正确抓取并显示中文网页,通常需要处理网页的字符编码。
自动检测编码 通常会自动根据响应头中的 -Type 来推测网页的编码,但有时可能不准确,此时可以使用 来自动检测编码。
执行以上代码,输出为:
utf-8
如果你知道网页的编码(例如 utf-8 或 gbk),可以直接设置 .:
response.encoding = 'utf-8' # 或者 'gbk',根据实际情况选择
查找标签
提供了多种方法来查找网页中的标签,最常用的包括 find() 和 ()。
输出结果类似如下:
新闻 ---------------------------- http://news.baidu.com ---------------------------- [新闻, hao123, 地图, 视频,
获取标签的文本
通过 () 方法,你可以提取标签中的文本内容:
实例
from bs4
# 指定你想要获取标题的网站
url = '' # 抓取bing搜索引擎的网页内容
# 发送HTTP请求获取网页内容
= .get(url)
# 中文乱码问题
. = 'utf-8'
soup = (.text, 'lxml')
# 获取第一个
标签中的文本内容
= soup.find('p').()
# 获取页面中所有文本内容
= soup.()
print()
输出结果类似如下:
百度一下,你就知道 ...
查找子标签和父标签你可以通过 和 属性访问标签的父标签和子标签:
# 获取当前标签的父标签parent_tag = first_link.parent # 获取当前标签的所有子标签 children = first_link.children

输出结果类似如下:
新闻 ---------------------------- 新闻 hao123 地图 视频 贴吧 登录 更多产品
查找具有特定属性的标签
你可以通过传递属性来查找具有特定属性的标签。
例如,查找类名为 -class 的所有 div 标签:
# 查找所有 class="example-class" 的标签 divs_with_class = soup.find_all('div', class_='example-class') # 查找具有 id="unique-id" 的标签 unique_paragraph = soup.find('p', id='unique-id')
获取搜索按钮,id 为 su :
输出结果为:
百度一下高级用法CSS 选择器
也支持通过 CSS 选择器来查找标签。
() 方法允许使用类似 的选择器语法来查找标签:
# 使用 CSS 选择器查找所有 class 为 'example' 的标签 example_divs = soup.select('div.example') # 查找所有 标签中的 href 属性 links = soup.select('a[href]')处理嵌套标签
支持深度嵌套的 HTML 结构,你可以通过递归查找子标签来处理这些结构:
# 查找嵌套的标签 nested_divs = soup.find_all('div', class_='nested') for div in nested_divs: print(div.get_text())修改网页内容
允许你修改 HTML 内容。
我们可以修改标签的属性、文本或删除标签:
转换为字符串
你可以将解析的 对象转换回 HTML 字符串:
# 转换为字符串 html_str = str(soup)属性与方法
以下是 中常用的属性和方法:
方法/属性描述示例
()
用于解析 HTML 或 XML 文档并返回一个 对象。
soup = (, 'html.')
.()
格式化并美化文档内容,生成结构化的字符串。
print(soup.())
.find()
查找第一个匹配的标签。
tag = soup.find('a')
.()
查找所有匹配的标签,返回一个列表。
tags = soup.('a')
.()
查找当前标签后所有符合条件的标签。
tags = soup.find('div').('p')
.()
查找当前标签前所有符合条件的标签。
tags = soup.find('div').('p')
.()
返回当前标签的父标签。
= tag.()
.()
查找当前标签的所有父标签。
= tag.()
.()
查找当前标签的下一个兄弟标签。
= tag.()
.g()
查找当前标签的前一个兄弟标签。
= tag.g()
.
获取当前标签的父标签。
= tag.
.
获取当前标签的下一个兄弟标签。
= tag.
.
获取当前标签的前一个兄弟标签。
= tag.
.()
提取标签内的文本内容,忽略所有HTML标签。
text = tag.()
.attrs
返回标签的所有属性,以字典形式表示。
href = tag.attrs
.
获取标签内的字符串内容。
= tag.
.name
返回标签的名称。
= tag.name
.
返回标签的所有子元素,以列表形式返回。
= tag.
标签 网页 查找 内容 获取 解析
热门文章
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
电脑恢复出厂设置步骤详解:备份数据及各操作要点
首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
张国立姜文甄子丹前妻曝光:明星家庭背后不为人知的辛酸
张国立姜文甄子丹前妻曝光:儿子是污点,干女儿争光
中国钢铁股票代码601005 重庆钢铁获宝武集团批复
网购怀孕B超单骗婚案曝光,定制逼真报告单竟如此简单?
AI预测胎儿长相服务走红,怀孕24周四维彩超图成关键
春季火灾防控:渝消蓝盾讲师团深入多地开展安全培训
电路板上key是什么意思?一篇文章看懂按键模块作用
论文数据出错别慌,联系编辑这样改最稳妥
张国立演艺路坎坷却总能逢凶化吉,生活中却有憋屈难题
如何让服务器自动下载网页图片并替换链接,超简单三步搞定
中科创投昆仑(新疆)能源有限公司何时上市及业务范围
钢铁股代码大全:88家上市公司名单一览